隨著互聯(lián)網(wǎng)銷售模式的快速發(fā)展,大數(shù)據(jù)直觀性分析已成為企業(yè)精準(zhǔn)推廣和提升產(chǎn)品銷量的關(guān)鍵工具。小紅書作為國內(nèi)領(lǐng)先的生活方式分享平臺(tái),聚集了大量年輕、高消費(fèi)力的用戶群體,為企業(yè)提供了寶貴的推廣渠道。結(jié)合大數(shù)據(jù)分析技術(shù),企業(yè)能夠高效實(shí)現(xiàn)產(chǎn)品推廣目標(biāo),具體體現(xiàn)在以下幾個(gè)方面。
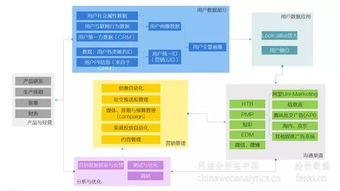
大數(shù)據(jù)直觀性分析幫助品牌精準(zhǔn)識(shí)別用戶畫像。通過對(duì)小紅書平臺(tái)用戶的行為數(shù)據(jù)、興趣標(biāo)簽和互動(dòng)記錄進(jìn)行分析,企業(yè)可以直觀地了解目標(biāo)消費(fèi)者的年齡、性別、地域、消費(fèi)偏好等特征。例如,通過數(shù)據(jù)可視化工具,品牌能夠快速識(shí)別哪些用戶對(duì)美妝、家居或時(shí)尚類產(chǎn)品更感興趣,從而制定針對(duì)性的內(nèi)容策略。這種精準(zhǔn)定位不僅提高了推廣內(nèi)容的吸引力,還降低了無效投放的成本。
大數(shù)據(jù)分析優(yōu)化內(nèi)容創(chuàng)作與傳播策略。在小紅書平臺(tái)上,用戶傾向于真實(shí)、生動(dòng)的分享體驗(yàn)。通過分析熱門筆記的關(guān)鍵詞、圖片風(fēng)格和互動(dòng)數(shù)據(jù),企業(yè)可以直觀地洞察用戶偏好,進(jìn)而創(chuàng)作更具共鳴的推廣內(nèi)容。例如,利用情感分析和趨勢(shì)預(yù)測(cè)工具,品牌可以及時(shí)捕捉流行話題,結(jié)合產(chǎn)品特點(diǎn)發(fā)布相關(guān)筆記,提升內(nèi)容的曝光率和轉(zhuǎn)化率。數(shù)據(jù)驅(qū)動(dòng)的策略確保內(nèi)容既能吸引用戶注意力,又能有效傳遞產(chǎn)品價(jià)值。
大數(shù)據(jù)直觀性分析助力推廣效果實(shí)時(shí)監(jiān)測(cè)與調(diào)整。通過整合銷售數(shù)據(jù)與平臺(tái)互動(dòng)指標(biāo),企業(yè)可以直觀追蹤推廣活動(dòng)的成效,如筆記瀏覽量、點(diǎn)贊數(shù)、收藏量以及直接銷售轉(zhuǎn)化率。借助儀表盤和報(bào)告工具,品牌能夠快速識(shí)別高績(jī)效內(nèi)容,并及時(shí)優(yōu)化低效環(huán)節(jié)。例如,如果數(shù)據(jù)顯示某類筆記在特定時(shí)間段內(nèi)互動(dòng)率較高,企業(yè)可加大資源投入,反之則調(diào)整方向,確保推廣資源最大化利用。
結(jié)合小紅書平臺(tái)的社交屬性,大數(shù)據(jù)分析還能強(qiáng)化用戶互動(dòng)與忠誠度建設(shè)。通過分析用戶評(píng)論和分享行為,企業(yè)可以識(shí)別潛在意見領(lǐng)袖(KOL)和忠實(shí)粉絲,開展合作或獎(jiǎng)勵(lì)計(jì)劃,進(jìn)一步提升品牌口碑和復(fù)購率。數(shù)據(jù)直觀呈現(xiàn)的用戶反饋,幫助企業(yè)快速響應(yīng)市場(chǎng)變化,建立長(zhǎng)期的客戶關(guān)系。
大數(shù)據(jù)直觀性分析在小紅書推廣中扮演著不可或缺的角色。通過精準(zhǔn)用戶識(shí)別、內(nèi)容優(yōu)化、效果監(jiān)測(cè)和互動(dòng)增強(qiáng),企業(yè)能夠有效提升產(chǎn)品在互聯(lián)網(wǎng)銷售中的競(jìng)爭(zhēng)力。隨著數(shù)據(jù)分析技術(shù)的不斷進(jìn)步,這一方法將更加智能化,為企業(yè)帶來更高效的銷售增長(zhǎng)。